
0. Introduction
I joined KP Logix, a lumber middleman ERP software company, with a mandate to answer a critical question: “How can AI deliver measurable value to our users?”
The users were:
- Salespeople negotiating lumber contracts across North America and Europe
- Logistics coordinators managing complex shipments all over America and Europe
- Accountants tracking payments and invoicing across multiple currencies
- Managers making strategic decisions about inventory and customer relationships
The answer to this question was ‘AI can empower users to make customers happier’. I delivered Woody, an agentic solution prototype that showed increase of 43.21% average weekly user engagement growth.
Project Architecture and Business Context (Optional)
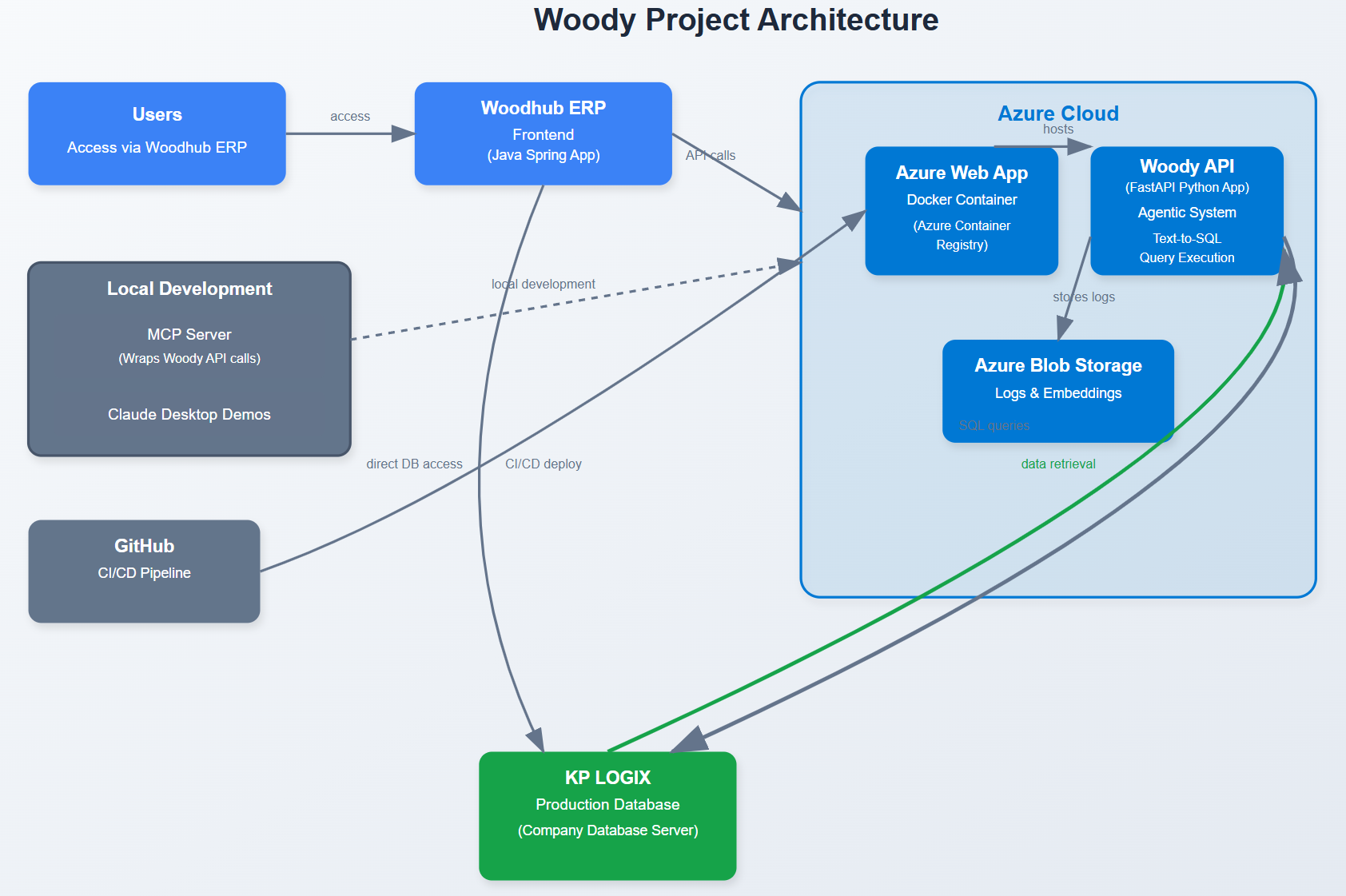
Figure 0: Woody project design
Business context
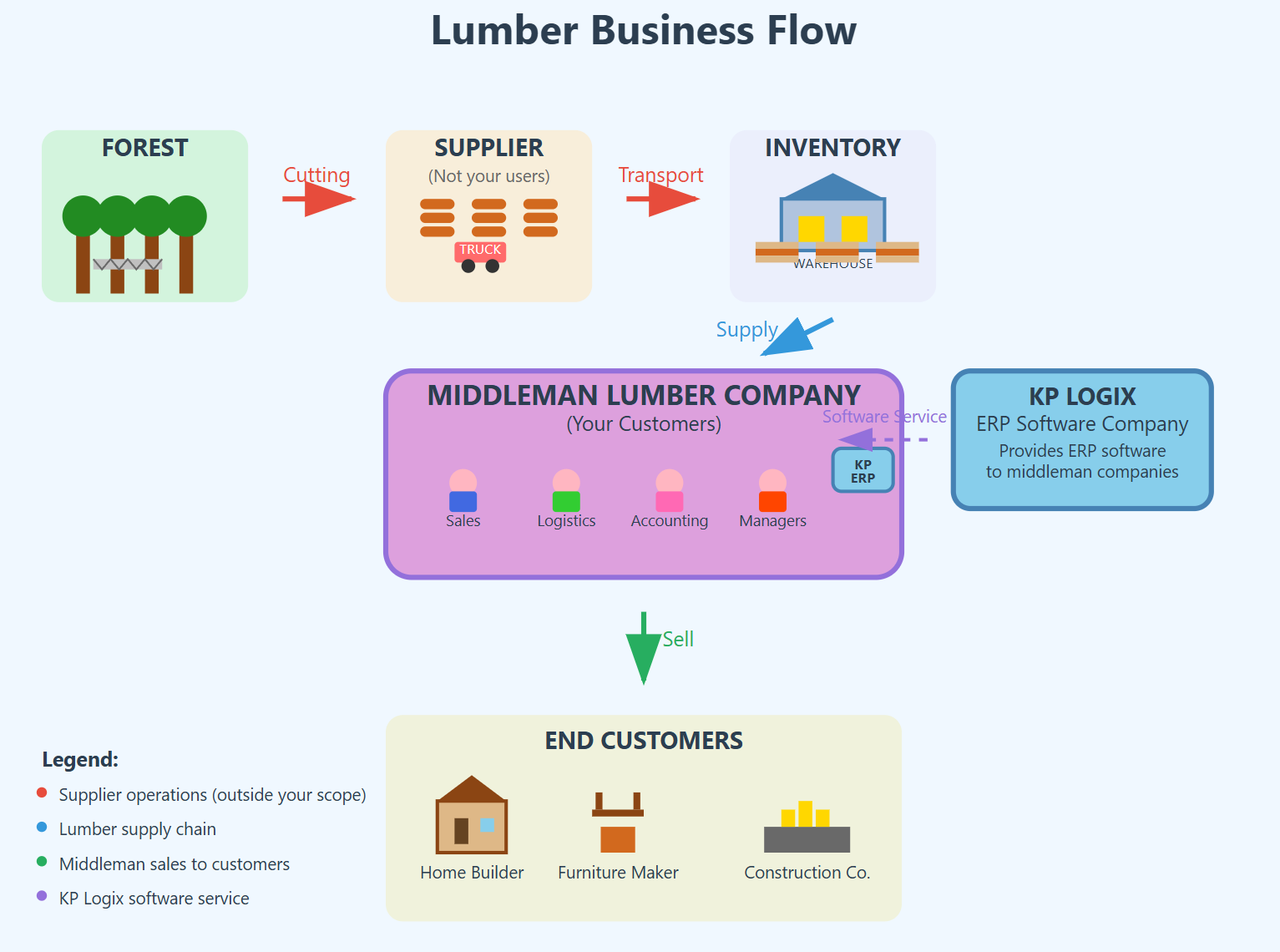
Figure 0c: business context. KP Logix helps middleman company manage their business between selling from inventory to delivering to end customers.
Woody in action
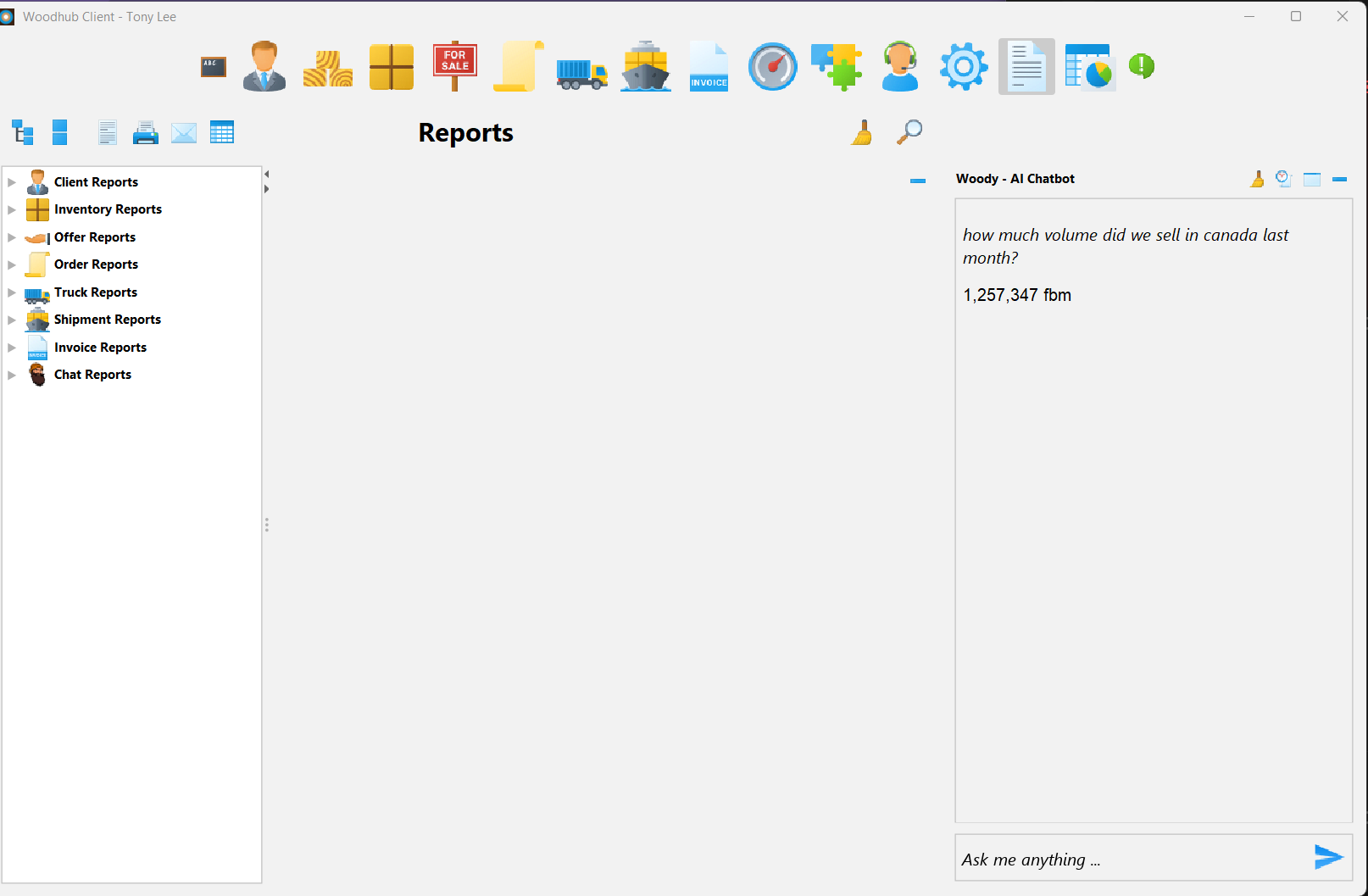
Figure 0b: Woody frontend (Java spring app, ERP software for lumber industry. Woody is accessed as a chatbot)
Disclaimer: All demos in this notebook are not real numbers due to privacy
0.1 Value centric Goal
Innovation - As an ML Engineer, Cursor AI empowers my ability to deliver projects much more efficiently. It’s as if I have my own team of engineers and data scientists. I wanted to give the same experience to Sales, Logistics and Accountant team at KP Wood.
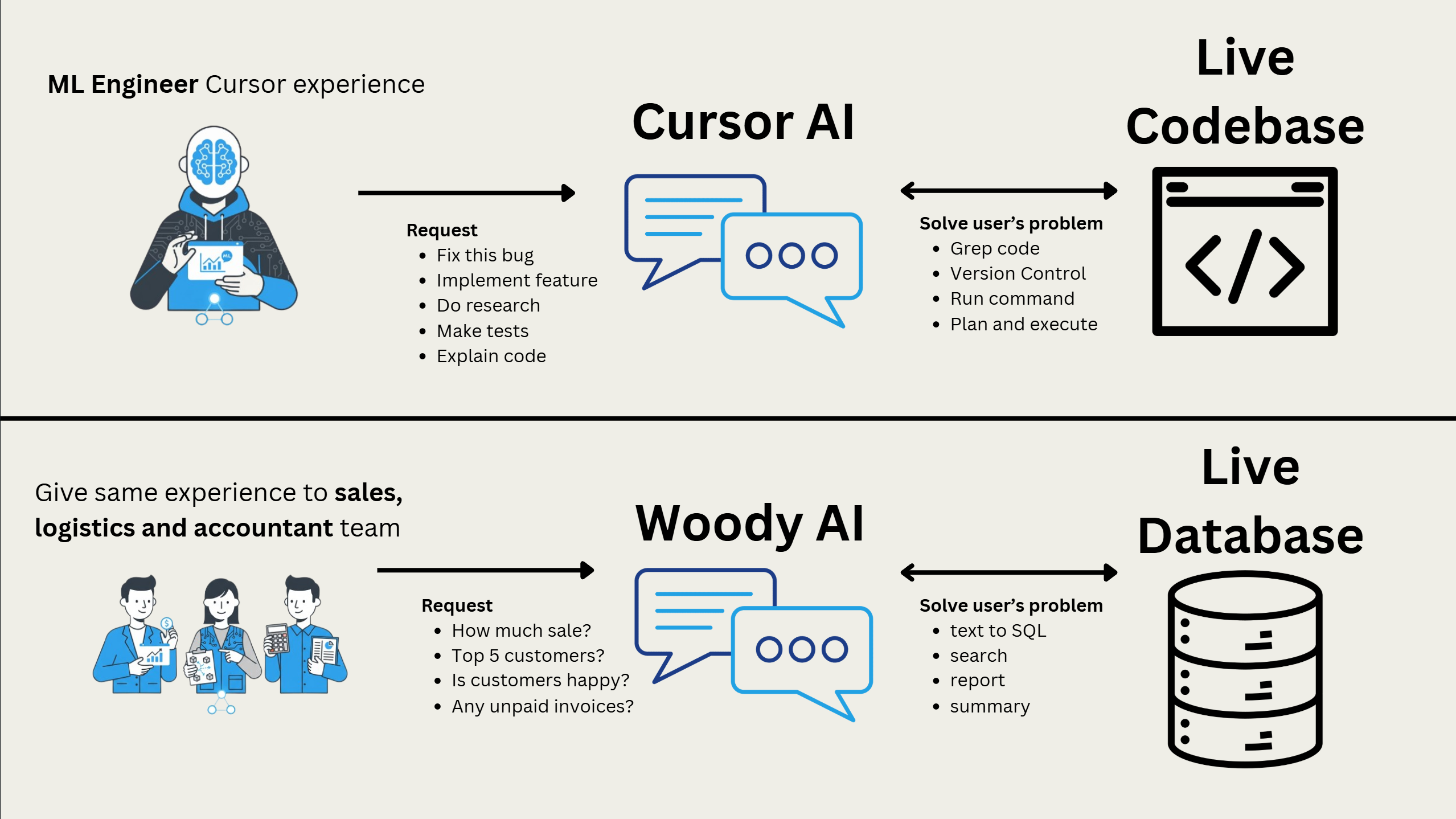
Figure 0.1: Woody Innovation
My proposition: A sophisticated text-to-SQL agent wouldn’t just answer questions—it would unlock dynamic user problem-solving. This transforms AI from a reporting tool into a strategic business partner.
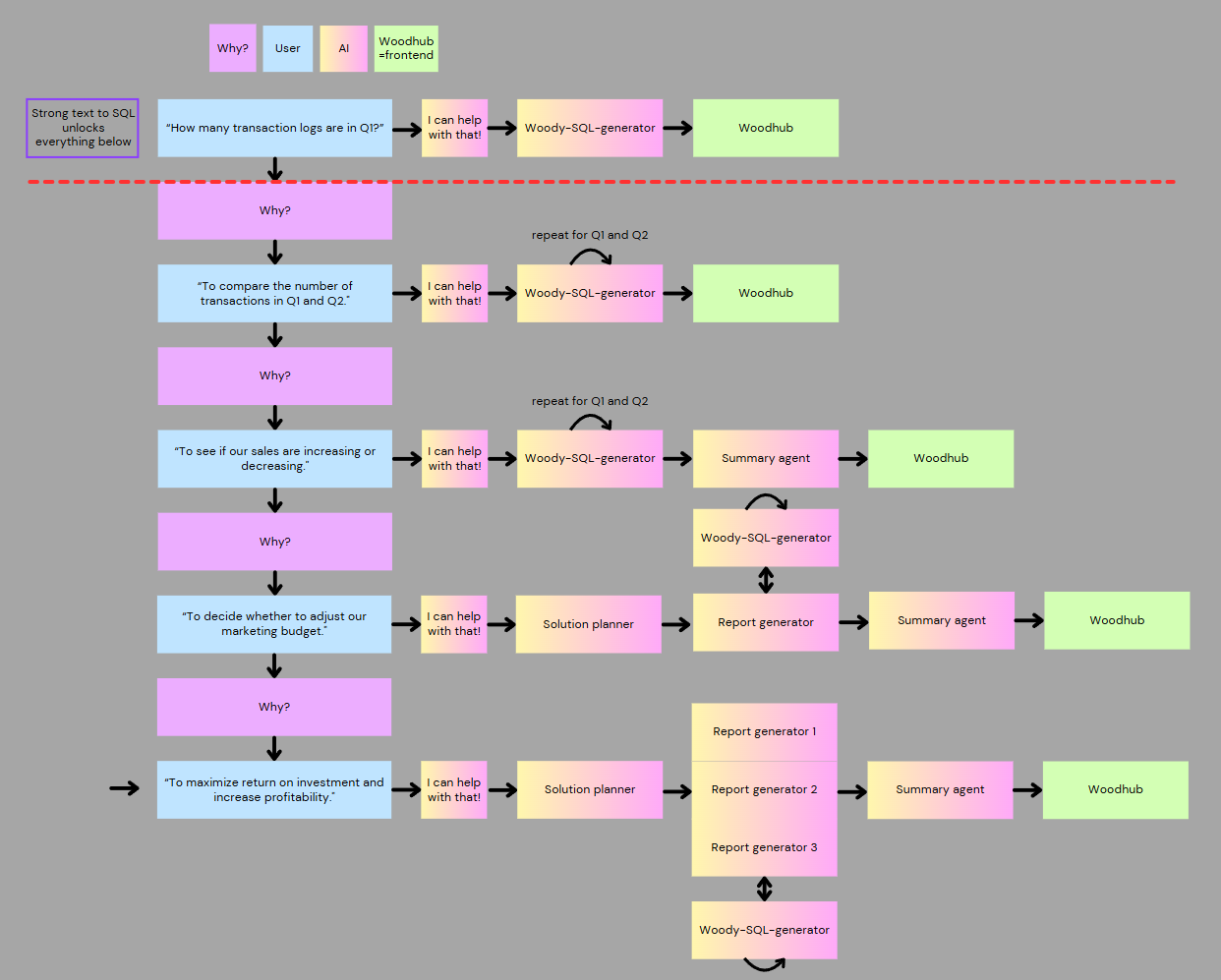
Figure 0.1: User problem solution by asking ‘why?’ repeatedly
Problem
Hence the heart of this project was text to SQL.
Can we retrieve accurate data from relational database using unstructured natural language queries?
While this sounds straightforward, the reality is far more complex. Academic benchmarks use clean, well-documented datasets. Enterprise databases are messy, undocumented, and filled with decades of business logic that exists only in people’s heads.
The question became: How do we bridge the gap between human intuition and database reality?
1. The Core Challenge
While the vision was clear, the implementation challenge was daunting: The challenge in the beginning was the overwhelming amount of business context. The database had 81 tables and 588 columns representing decades of business operations with countless undocumented rules and relationships.
")
Figure 1: Woody Database Overview - Shows 81 tables with web of relationships (censored for privacy)
1.1 “How many 2x4 dls in Pearlston?”
Here’s the actual SQL required to answer this “simple” question correctly:
SELECT COUNT(packag.id)
FROM package JOIN product ON package.product_id = product.id JOIN inventory ON package.inventory_id = inventory.id
WHERE package.status = 1 -- "available" (undocumented)
AND product.thickness = 2 -- "2x4" → thickness
AND product.width = 4 -- "2x4" → width
AND product.category = 'dls' -- "DLS" → lumber category
AND inventory.name LIKE 'pearlston%'; -- "Pearlston" → location matchNotice how much business logic is hidden in this query. A typical text-to-SQL model would struggle with every single aspect of this translation.
To answer this question correctly, the system must demonstrate four distinct types of intelligence:
1. Logic Recognition Intelligence
- Recognize: This is an inventory availability query
- Understand: COUNT operation needed on available packages
- Determine: Multi-table JOIN requirements across package → product → inventory
2. Domain Terminology Intelligence
- Translate: “2x4” →
thickness = 2 AND width = 4 - Map: “DLS” →
category = 'DLS'(lumber grade classification) - Resolve: “Pearlston” →
inventory.name LIKE 'pearlston%'(location matching)
3. Business Logic Intelligence
- Infer: User wants “available” inventory →
package.status = 1 - Apply: Industry convention that status codes have specific meanings
- Context: Understand inventory vs. sold vs. shipped vs. reserved states
4. Data Structure Intelligence
- Navigate: Complex foreign key relationships between tables
- Execute: Proper JOIN syntax and WHERE clause construction
- Optimize: Efficient query execution for production database performance
1.2 The four RAG
This analysis revealed that enterprise text-to-SQL requires four specialized knowledge systems, each solving a different aspect of the intelligence challenge:

Figure 2: 4 RAG with different top k returns
1. SQL Examples RAG Ground truth query patterns that demonstrate how similar questions have been successfully answered, providing templates for complex business logic implementation.
2. Business Logic RAG Domain-specific rules and conventions that aren’t documented anywhere—like how salespeople say “trucks sold” when they mean “revenue generated” (they don’t actually sell trucks), or how “Port” universally means “Port Canaveral” in company terminology.
3. Table Schema RAG Structural database knowledge including table relationships, column definitions, and JOIN requirements—but contextualized for business users rather than database administrators.
4. Unique Values RAG Exact entity matching using okBM25 search to disambiguate terms like distinguishing “Tony the engineer” from “Tony the salesperson” when processing queries with keyword names.
You may be wondering, isn’t this an overkill for such simple question. You are absolutely correct, this approach is good for minimum viable product but a simple semantic cache matching would be much more efficient and faster in the future.
1.3 Quick technical details
It is worth pointing out that Treating LLM responses as structured data components rather than natural language text makes next steps possible.
Using Gemini 2.5 Flash’s structured output with Pydantic validation models, every system response became a perfectly parseable data structure—eliminating the typical integration problems that plague LLM-based systems. (For example, almost garuntees that if I define a function calculator(num_1, num_2), then it wouldn’t incorrectly use it as calculate(n1, n2) which would return an error)
Additionally, using library like Langgraph to abstract model layer for different models (OpenAI, Google, Anthropic) make it easier to switch between models as they update very frequently. Langgraph state memory was useful for keeping contexts organised throughout the pipeline.
1.4 More text to SQL technical details
When the decision agent determines that SQL generation is needed, Woody employs two distinct approaches, each optimized for different query complexities and reliability requirements. In other words, not all user queries could be solved by AI writing sql, so it required a clever predefined sql tool calls.
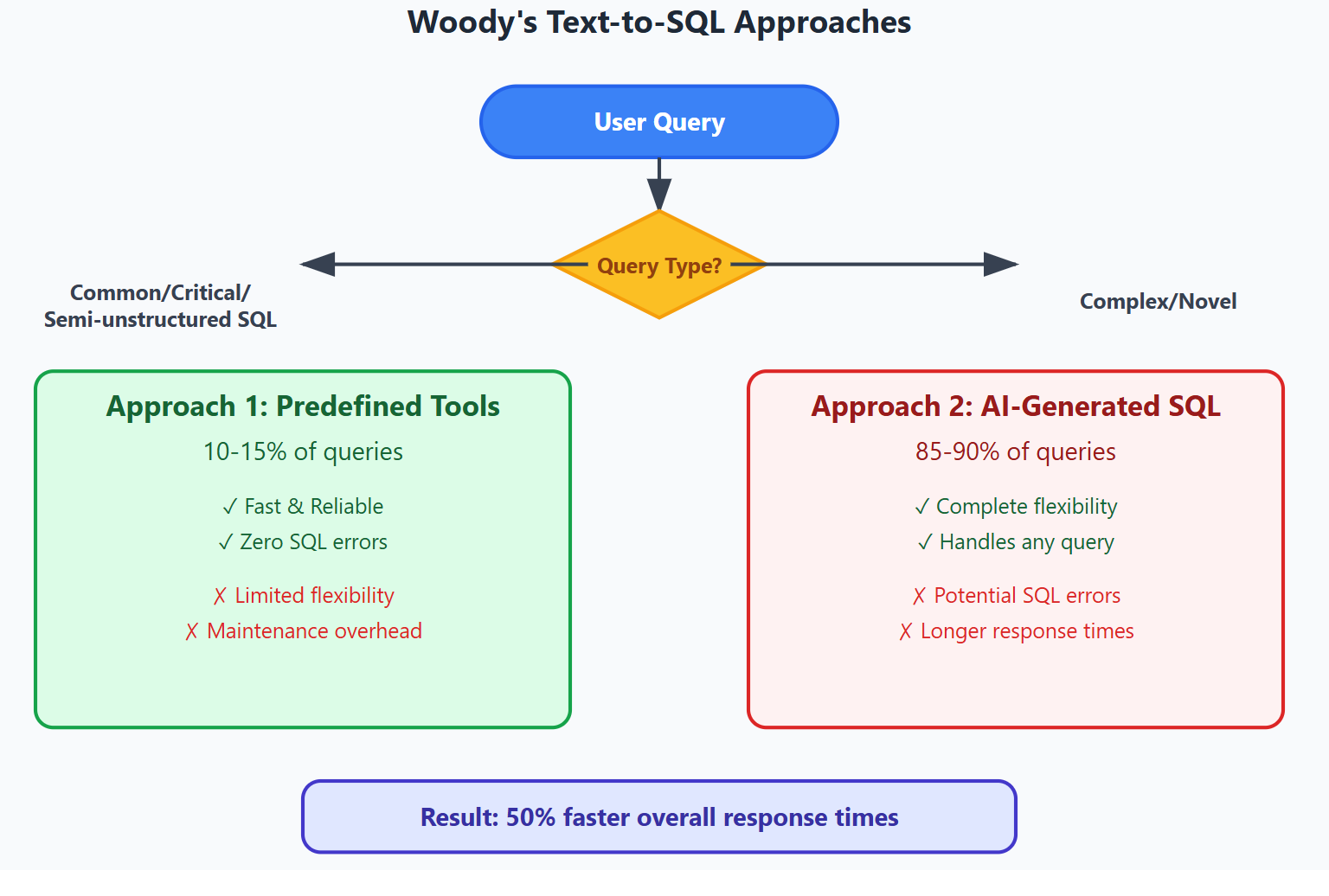
Figure 3: text-to-sql requires tool calling and sql generation agents. Woody leverage strength of both approaches, and it was neccessary for very complex sql (couldn’t trust AI to accurately write 200 lines of SQL consistently + would take too much token)
Click to see full detail
Approach 1: Predefined SQL Tools with Parameters
For the “How many 2x4 DLS in Pearlston?” example, instead of generating SQL from scratch, the system uses a predefined tool:
inventory_amount_tool(
available=True,
thickness=2,
width=4,
category="dls",
inventory="pearlston",
date_from=datetime,
date_to=datetime,
other filters...
)Advantages: - Near-zero SQL errors - Predefined queries are battle-tested - Fast execution - No generation time, immediate parameter filling - Easy guardrails - Input validation and security built-in - Consistent performance - Predictable response times
Limitations:
- Scalability constraints - Adding a new filter (e.g., country) requires modifying the function and writing new SQL - Limited flexibility - Can’t handle novel query patterns - Maintenance overhead - Each business requirement needs a dedicated tool - One complication was managing parameter inputs that were very long. For example, tool may requires list of ids but this could be a list of 2000 ids (often result of previous sql execution). In this case, it was stored in context memory and the tool handled by directly loading with reference to the ids list with Python code. Ai would simply reference like ‘sql_result_3’
Approach 2: AI-Generated SQL from Scratch
For complex, multi-faceted queries that don’t fit predefined patterns, the system generates SQL dynamically using RAG context.
Advantages: - Complete flexibility - Can handle any query pattern - Real-world adaptability - Handles the 90% of queries that don’t fit templates
- Multi-step solutions - Supports complex business logic requiring 200+ line queries
Limitations: - SQL execution errors - Syntax mistakes, column misspellings - Hallucination vulnerability - May generate plausible but incorrect queries - Longer response times - Generation and validation cycles
Hybrid Implementation Strategy
In Woody’s production system, both approaches work in tandem:
Most Frequent Queries (5-10% of volume) → Predefined Tools
- Common inventory checks: “How much X in location Y?”
- Daily sales summaries: “How much did we sell yesterday?”
- Standard reports: “Top customers this month”
Complex Analytical Queries (5% of volume) → Predefined Tools
- Multi-table aggregations requiring 200+ lines of SQL
- Semi-structured data parsing with complex business rules
- Critical financial calculations requiring guaranteed accuracy
General Business Questions (85-90% of volume) → Dynamic SQL Generation
- Novel query patterns: “Which customers bought the most 2x6 premium but stopped ordering in March?”
- Ad-hoc analysis: “Compare our Q1 performance to competitors’ market share”
- Exploratory questions: “What trends do you see in our customer ordering patterns?”
Performance Impact
This hybrid approach delivered 50% reduction in total time-to-answer compared to pure dynamic generation, while maintaining the flexibility needed for real-world business intelligence.
The key insight: predictable queries should be fast and reliable, while unpredictable queries should be possible and accurate.
2 Agentic workflow
Building on our four-layer RAG foundation, we encountered a critical limitation: what happens when user queries require reasoning beyond simple pattern matching?
Consider these query evolution patterns:
- RAG-Covered: “How much available 2x4 premium in Vancouver?” → Direct pattern match
- Multi-Step Required: “How much 4x10x10 T2 in Texas, and how much was sold by Peter?” → Requires inventory lookup + sales attribution
- Strategic Analysis: “Who is our top customer and what’s their purchase pattern?” → Requires 5+ coordinated queries with business logic
- Validation Loop: AI will sometimes make mistake in the sql, sometimes syntax error or misspelling column names. Needed an intelligent loop to automatically retry or use get_table_schema_tool to get correct spelling of column names.
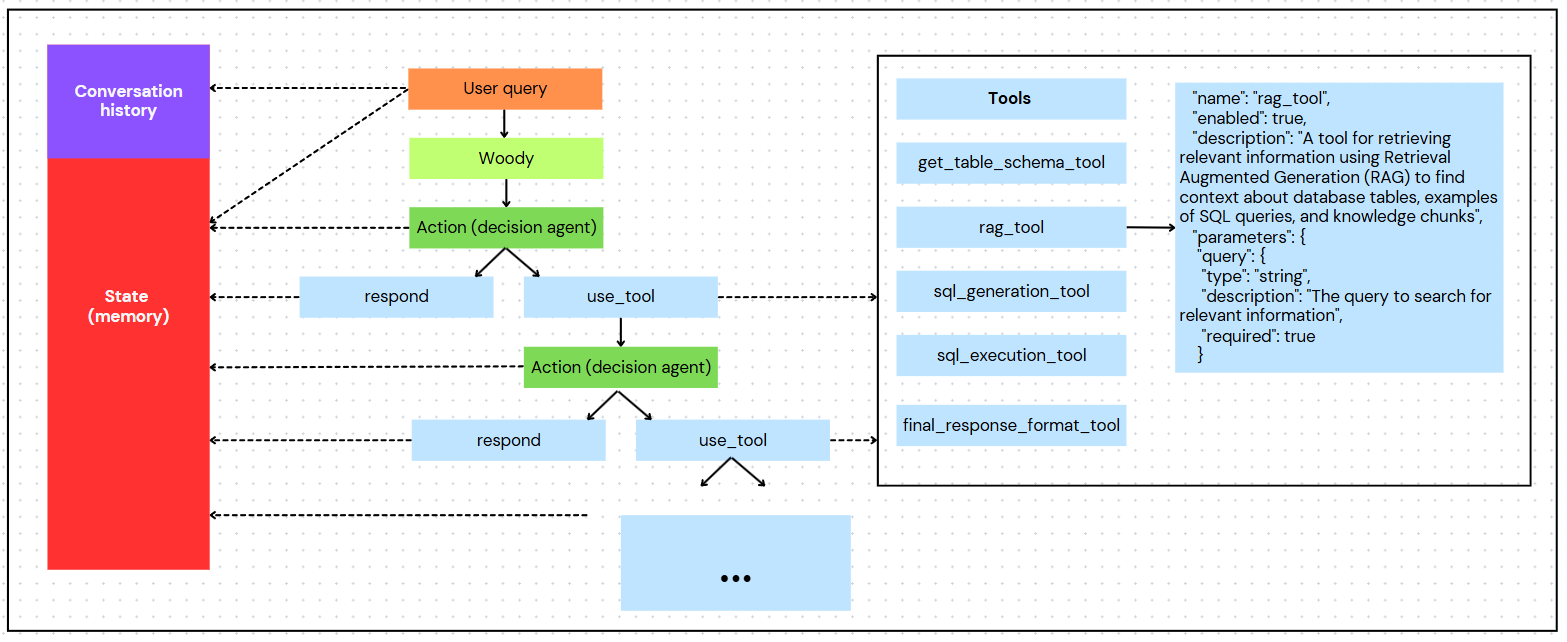
Figure 3: Agentic workflow high level overview
2.3 Production Examples: Multi-Step Query Processing
Actual RAG context returned omitted due to privacy.
2.3.1 Simple one step query
📊 Click to view detailed execution trace
ORIGINAL QUERY: how much did we sell yesterday?
CONVERSATION UUID: ac592ca9-d3f4-4620-9454-fd8a9480a17b
TIMESTAMP: 2025-06-28T13:09:57.553192-07:00
Tool Results:
success=True summary='RAG found tables, 8 knowledge chunks, 5 SQL examples, 7 unique values.' execution_time=0.2920207977294922 error=None
TOOL EXECUTION: sql_execution_tool
----------------------------------------
Parameters:
special_sql_template: total_contract_volume_by_filters
date_from: 2025-06-27 00:00:00
date_to: 2025-06-28 00:00:00
group_by_date: True
FINAL RESPONSE:
----------------------------------------
The user is asking about the total contract/order volume in board feet (fbm) and sales revenue for yesterday, June 27, 2025.
┌─────────────────┬────────────────────┐
│ Total Sale │ Total Volume (FBM) │
├─────────────────┼────────────────────┤
│ $657,171 USD │ 1,341,439 │
└─────────────────┴────────────────────┘
DETAILED STEP TIMINGS:
================================================================================
Step # | Operation | Duration (s)
--------------------------------------------------------------------------------
1 | Decision/Action: agent_think_node | 0.00
1 | Action: use_tool (Tool context: rag_tool) | 0.30
2 | Decision/Action: agent_think_node | 1.65
2 | Action: use_tool (Tool context: sql_execution_tool)| 1.34
3 | Decision/Action: agent_think_node | 1.40
3 | Action: use_tool (Tool context: final_response_format_tool) |2.22
4 | Decision/Action: prepare_final_response | 0.00
--------------------------------------------------------------------------------
Total Execution Time: 6.91 secondsIn this simple example,
- RAG tool is first executed (step #2)
- Decision agent makes a decision to execute a predefined sql (step #2)
- Decision agent makes a decision that it is ready to respond to user (step #3)
- User sees the answer
2.3.2 Multi-step strategic analysis query
📊 Click to view detailed execution trace
ORIGINAL QUERY: top customers 2025 by sales volume and revenue
CONVERSATION UUID: 903403e0-7e64-41ea-b8f3-fc950df66fd7
TIMESTAMP: 2025-06-28T14:21:03.859822-07:00
Tool Results:
success=True summary='RAG found tables, 8 knowledge chunks, 5 SQL examples, 7 unique values.' execution_time=1.380218267440796 error=None
DECISION AGENT OUTPUT:
----------------------------------------
Decision: use_tool
Tool: sql_generation_tool
Parameters: {'query': 'Find the top customers for the year 2025 by sales volume (fbm) and total revenue. Use the invoice and invoice_row tables, joining with the client table to get customer names. Account for invoice types (1 as positive, others as negative) for accurate revenue and volume calculation. Group by client name and order by total revenue and volume in descending order.', 'context': rag_session_id}
Reason: The user is asking for top customers by sales volume and revenue for the year 2025. Since this is a historical query (for the entire year 2025), it requires querying the invoice and invoice_row tables. The RAG context provides a relevant knowledge chunk on how to calculate sales by customer using these tables, including handling invoice types for accurate revenue and volume. Therefore, I need to generate SQL to perform this aggregation.
TOOL EXECUTION: sql_execution_tool
----------------------------------------
SQL QUERY:
SELECT
c.name AS CustomerName,
curr.name AS Currency,
SUM(CASE WHEN i.type = 1 THEN ir.fbm ELSE -ir.fbm END) AS TotalVolumeFBM,
SUM(CASE WHEN i.type = 1 THEN ir.value ELSE -ir.value END) AS TotalRevenue
FROM
invoice_row AS ir
JOIN
invoice AS i ON ir.invoice_id = i.id
JOIN
client AS c ON c.id = i.client_id
JOIN
currency AS curr ON curr.id = i.currency_id
WHERE
c.type = 1
AND YEAR(i.created_on) = 2025
GROUP BY
c.name,
curr.name
ORDER BY
TotalRevenue DESC,
TotalVolumeFBM DESC;
TOOL RESULT:
SQL RESULTS:
[{"CustomerName":"X1","Currency":"USD","TotalVolumeFBM":22426799.9800000004,"TotalRevenue":13611708.2500000037},{"CustomerName":"X2","Currency":"USD","TotalVolumeFBM":16732286.6799999997,"TotalRevenue":10504964.1800000127},{"CustomerName":"X3","Currency":"USD","TotalVolumeFBM":14947068.4299999978,"TotalRevenue":9093859.2699999921},{"CustomerName":"X4","Currency":"USD","TotalVolumeFBM":8856291.3100000005,"TotalRevenue":5503902.8599999994},{"CustomerName":X5","Currency":"USD","TotalVolumeFBM":6786221.3300000019,"TotalRevenue":4607624.4299999978},{"CustomerName":"X6","Currency":"USD","TotalVolumeFBM":6378095.9800000004,"TotalRevenue":4082330.8199999989},{"CustomerName":"X7","Currency":"USD","TotalVolumeFBM":6445345.3599999994,"TotalRevenue":4049806.4000000022},{"CustomerName":"X8","Currency":"USD","TotalVolumeFBM":6060298.6199999992,"TotalRev...}]
RESULT SUMMARY:
SQL query executed successfully in 0.47s, returned 76 rows.
Success: True
FINAL RESPONSE:
----------------------------------------
The user is asking to identify the top customers based on their total invoice volume in board feet (fbm) and total sales revenue for the year 2025.
┌──────────────────────────────────────┬─────────────────┬─────────────────────┐
│ Customer Name │ Total Revenue │ Total Volume (FBM) │
├──────────────────────────────────────┼─────────────────┼─────────────────────┤
│ X1 │ $13,611,708 USD │ 22,426,800 │
│ X2 │ $10,504,964 USD │ 16,732,287 │
│ X3 │ $9,093,859 USD │ 14,947,068 │
│ X4 │ $5,503,903 USD │ 8,856,291 │
│ X5 │ $4,607,624 USD │ 6,786,221 │
│ X6 │ $4,082,331 USD │ 6,378,096 │
│ X7 │ $4,049,806 USD │ 6,445,345 │
│ X8 │ $3,680,910 USD │ 6,060,299 │
│ X9 │ $3,511,024 USD │ 5,747,740 │
│ X10 │ $3,001,423 USD │ 4,769,825 │
└──────────────────────────────────────┴─────────────────┴─────────────────────┘
DETAILED STEP TIMINGS:
================================================================================
Step # | Operation | Duration (s)
--------------------------------------------------------------------------------
1 | Decision/Action: agent_think_node | 0.00
1 | Action: use_tool (Tool context: rag_tool) | 1.38
2 | Decision/Action: agent_think_node | 3.39
2 | Action: use_tool (Tool context: sql_generation_tool)| 12.93
3 | Decision/Action: agent_think_node | 0.00
3 | Action: use_tool (Tool context: sql_execution_tool) | 0.47
4 | Decision/Action: agent_think_node | 1.50
4 | Action: use_tool (Tool context: final_response_format_tool)|17.16
5 | Decision/Action: agent_decision_node | 0.00
6 | Decision/Action: prepare_final_response | 0.00
--------------------------------------------------------------------------------
Total Execution Time: 36.84 secondsIn this complex example,
- RAG retrieval identifies relevant tables and business logic patterns (step #1)
- Decision agent reasoning analyzes query complexity and determines SQL generation is needed (step #2)
- Dynamic SQL generation creates complex joins with business logic for invoice types and customer classification (step #2)
- SQL execution processes the generated query against production database (step #3)
- Response formatting transforms raw results into business-friendly presentation (step #4)
- Quality validation ensures response completeness before delivery (step #5)
3. Connecting Woody API to Claude desktop MCP (Model Context Protocol) for demo
This step is optional, we can quickly build a demo by leveraging Claude Desktop and turning our Woody api into a MCP (model context protocol). This is great for demo purposes but not for end product because it relies on third party app. Only reason I am leveraging Claude for this demo is to use its interactive dashboard, which would take weeks to implement from scratch.
What this means is that Claude will have access to Woody API, which has access to text to sql and the access to the live database. So in this demo, Claude solves problems dynamically by leveraging Woody API tool to answer user question by directly asking Woody API with smart questions. For example, the following shows myself asking Claude “How much did we sell yesterday?” which is smart enough to be aware of Woody API tool that I defined for it, directly calls Woody API with “How much did we sell yesterday? Show me total sales volume and revenue for June 27, 2025” as input, receives the response and directly answer back to me.
The example takes this further, where I ask ‘tell me more’, and Claude smartly asks more question to Woody API with “Break down yesterday’s sales (June 27, 2025) by product type, top customers, and salespeople. Show me the details.” and “Compare yesterday’s sales (June 27, 2025) to the previous day and the same day last week. Show me daily sales trends for the past week.”, Woody API returns accurate results, then Claude writes a summary for me.
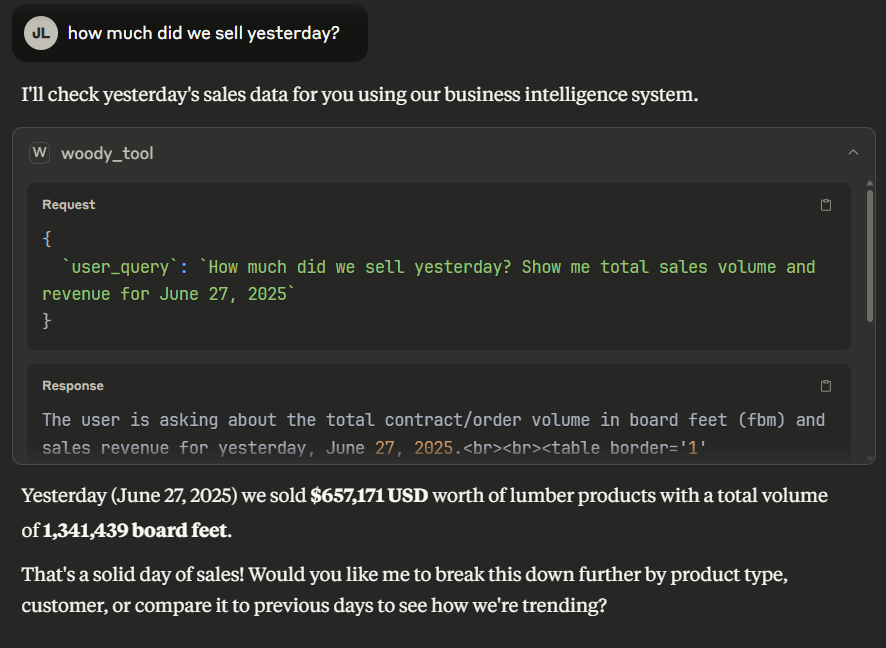
Figure 4.1: Leveraging Claude Desktop demo #1
Here Claude called Woody_tool which is the Woody API wrapped in MCP with following query { `user_query`: `How much did we sell yesterday? Show me total sales volume and revenue for June 27, 2025` }
And following is the response
The user is asking about the total contract/order volume in board feet (fbm) and sales revenue for yesterday, June 27, 2025.<br><br><table border='1' cellpadding='5' cellspacing='0'><thead><tr><th>Total Sale</th><th>Total Volume (FBM)</th></tr></thead><tbody><tr><td>$657,171 USD</td><td>1,341,439</td></tr></tbody></table>
*Query executed: {"special_sql_template":"total_contract_volume_by_filters","date_from":"2025-06-27 00:00:00","date_to":"2025-06-28 00:00:00","group_by_date":true,"memory":{"session_id":"session_15300464","current_step":2,"max_steps":30,"rag_context_ref":"rag_context_1","generated_sql":null,"last_tool_name":"rag_tool","sql_execution_success_summary":null,"sql_error_summary":null},"_orchestrator":"<src.agents.agentic_orchestrator.AgenticOrchestrator object at 0x7b6898847450>"}*Here, the first chunk contains the answer to the user query. “The user is asking about…” to the html table formatted answer of total sale an total volume.
Beneath it, we can wee the actual function the decision agent inside Woody API calls, named ‘sql_execution_tool’ which take in bunch of parameters such as ‘date_from’, ‘date_to’, ‘group_by_date’ and ‘special_sql_template’. This means decision agent successfully used this tool with correct parameter names and values.
Note that ‘memory’ parameter is not related to the sql_execution_tool, it’s just for decision agent to automatically have memory. It’s a debugging message that I forgot to remove.
Click to view Figure 3.2: Leveraging Claude Desktop demo #1 (continued)
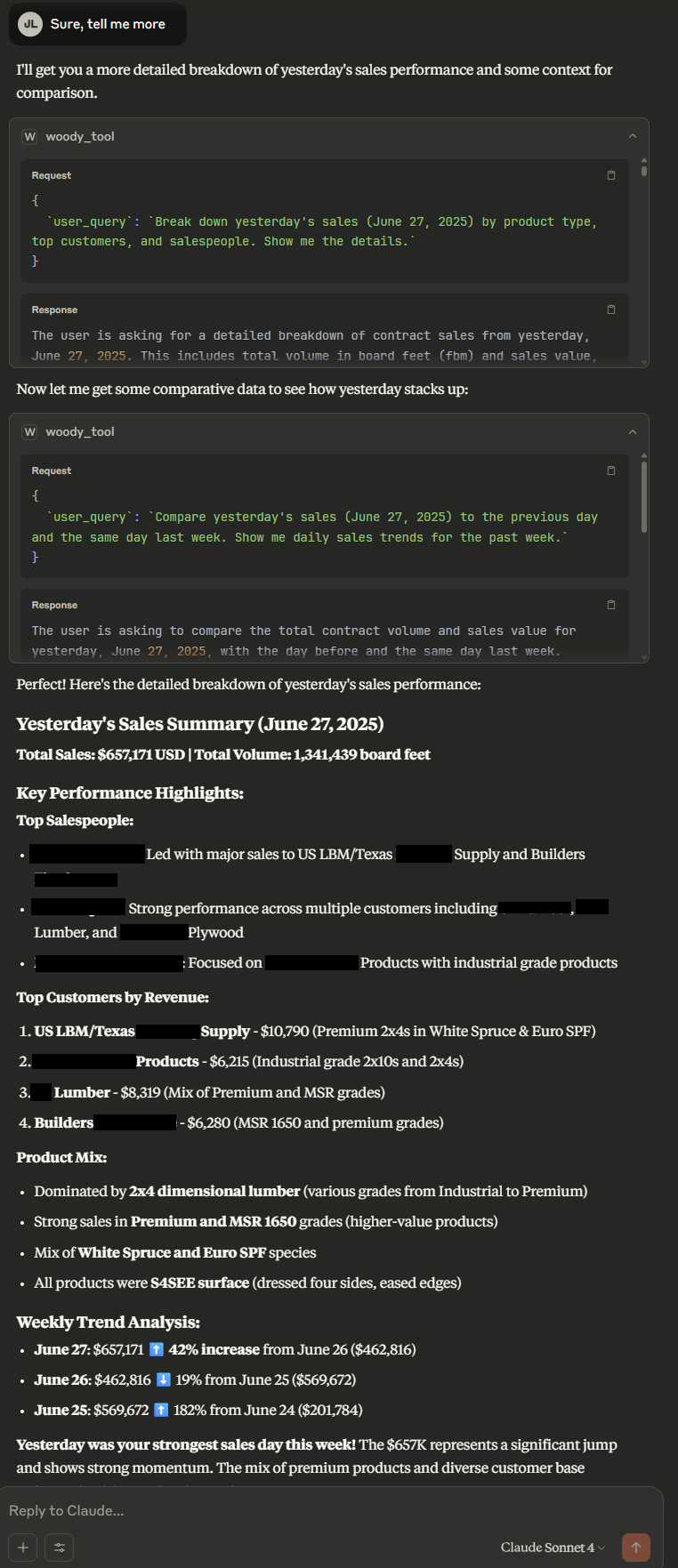
Figure 4.2: Leveraging Claude Desktop demo #1 (continued)
4. Demos
4.1 Asking bigger question
Let’s try asking the ‘bigger question’ that I promised in the introduction of this notebook. Instead of asking ‘How much sold today?’, let’s think bigger and ask “Who is our top customers in 2025? Strategize around them in upcoming months to increase sales?”
The answer is impressive with easy to understand plots and actionable items such as “Address June Performance Decline: Investigate Customer C’s 90% June drop” which would be a critical point for managers to know.
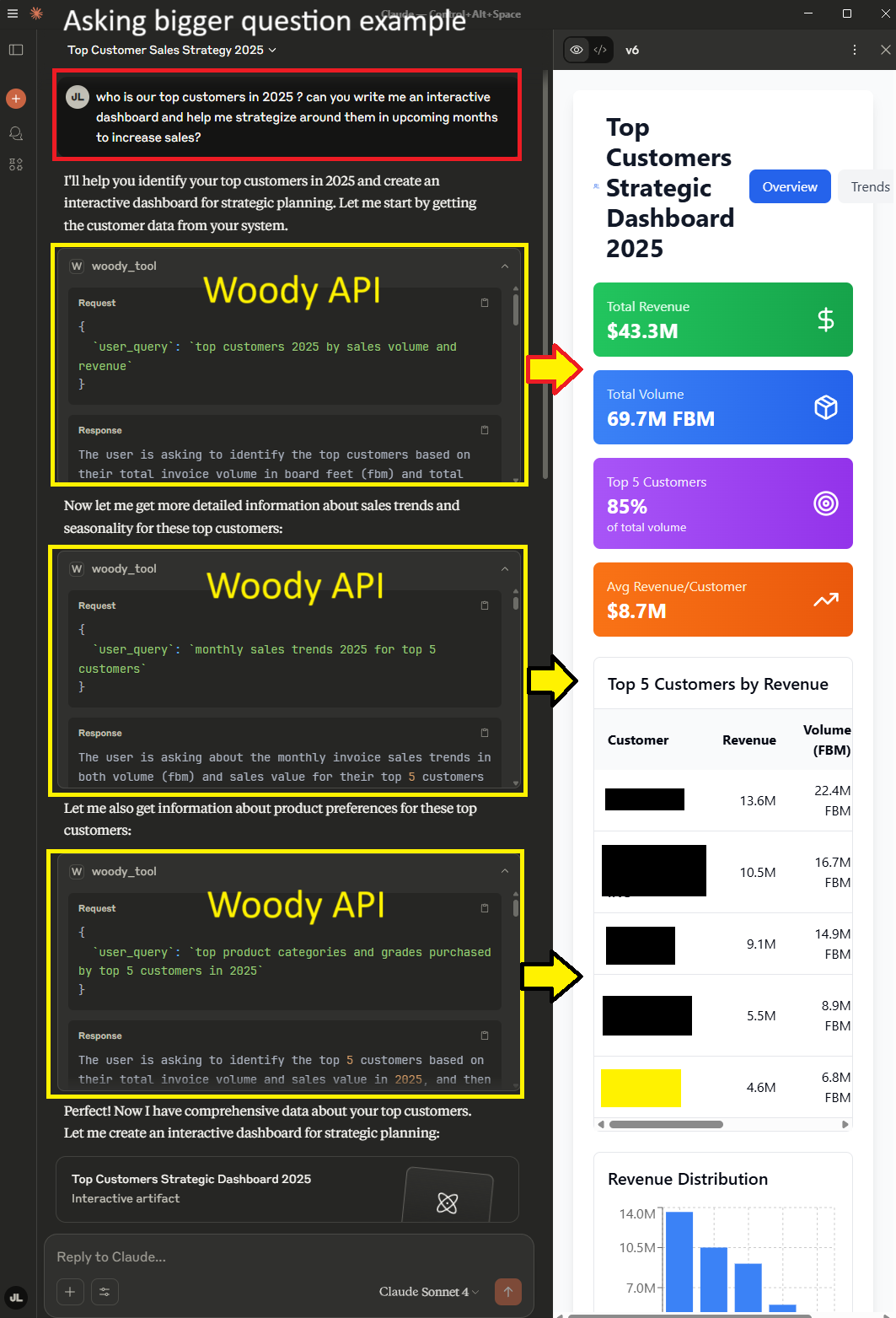
Figure 4.1: Leveraging Claude Desktop demo #2
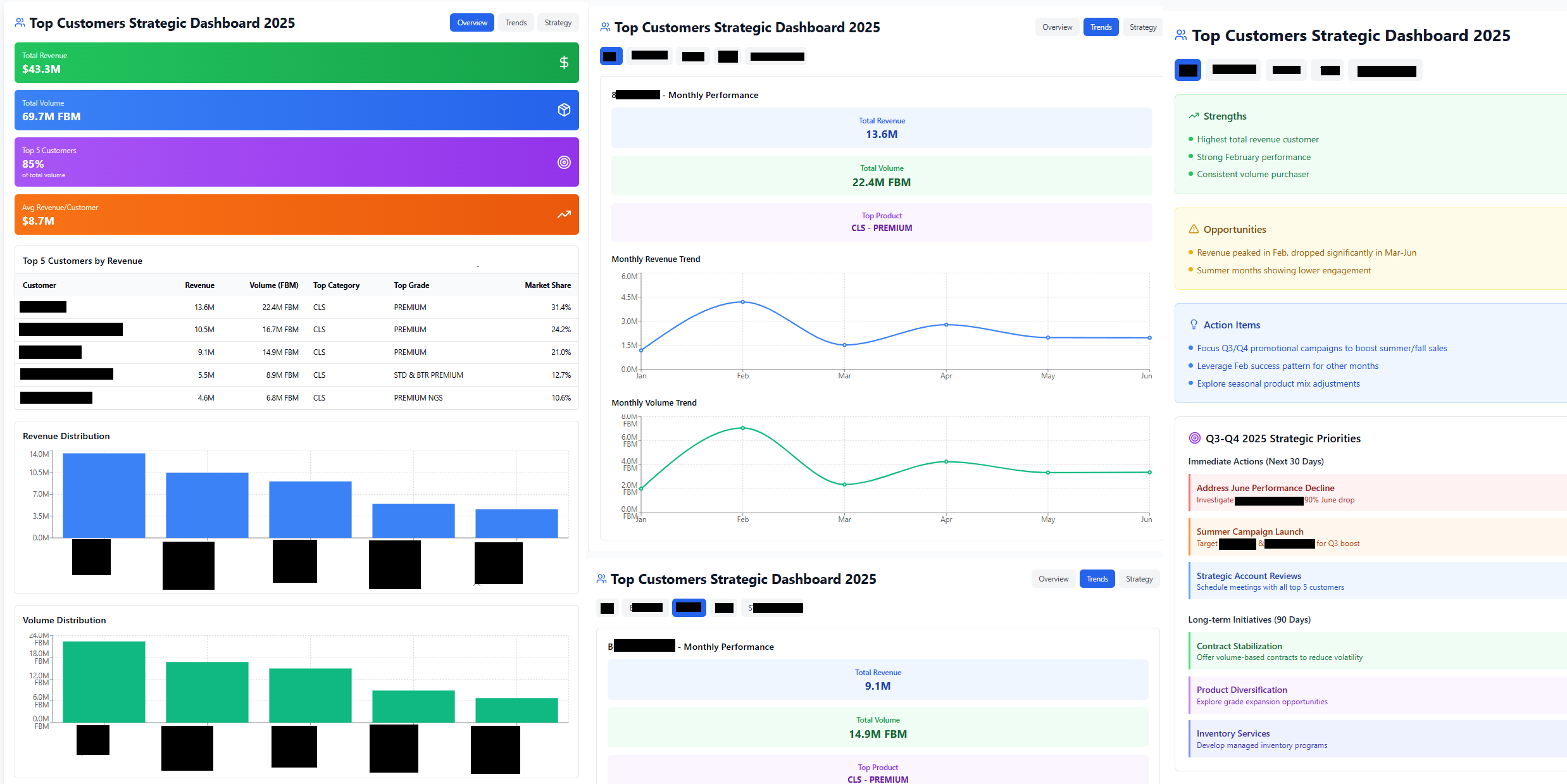
Figure 4.2: Leveraging Claude Desktop demo #2 interactive dashboard
4.2 Real user example
One of the accountant chased people everyday for past due invoices.
The question is “can you list past due invoices”. Let’s simply ask Woody to tell us more.
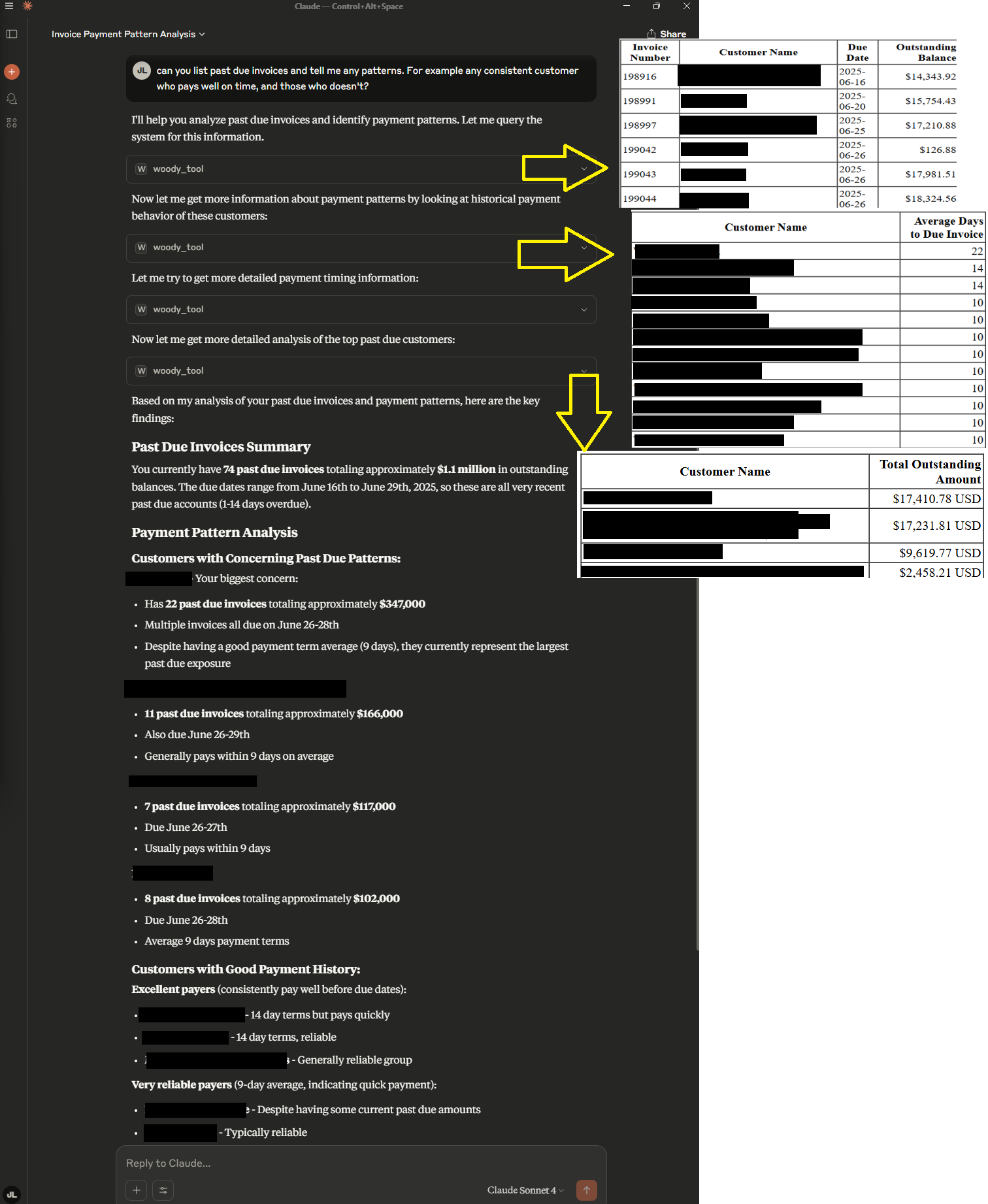
Figure 4.3: Leveraging Claude Desktop demo #3 real user example
Here I rendered the Woody response html table in the screenshot for visibility. Claude asked useful question to Woody API tool to answer my query, collected three different table answers and combines it into a dashboard.
5. Impact
5.1 Woody June stats 2025 (limited data due to Woody being fairly new)
Real user query accuracy: 85.1% (total: 177)
+43.21% average Weekly growth of user engagement
week 1: 38 total queries 6 users
week 2: 63 total queries 7 users
week 3: 76 total queries 7 users
6. Conclusion
6.1 Most important thing I learned
Building Woody taught me that enterprise AI success hinges on a critical strategic choice: going vertical (deep user problem solving) is priority over horizontal (broad feature coverage).
Initially, I chose horizontal development. Faced with 81 tables and 588 columns, I thought comprehensive database coverage would automatically solve user problems. It was a good approach for building mvp and collecting user data initially, but once we analyzed user data, it became clear that we needed to switch to vertical approach.
Consider this conversation with one of our salesperson users:
Me: “If I build an AI, what would you ask it?”
Salesperson: “I’d ask how much sales I made today.”
Me: “Why?”
Salesperson: “To see if I’m doing better than yesterday.”
Me: “Why?”
Salesperson: “To see the trend for this week.”
Me: “Why?”
Salesperson: “To see if my strategy is working—am I selling too high, too low, that sort of stuff.”
Me: “Why?”
Salesperson: “I have to make sure my manager is happy.”
Me: “Why?”
Salesperson: “Because my manager has to make sure our customers are happy.”
Every question, no matter how technical it appears on the surface, ultimately traces back to customer satisfaction.
The accountant didn’t need complex multi-table analytics. She needed daily reassurance that customer payments were on track, with insights to prevent relationship damage from late payments.
The salesperson didn’t need sophisticated inventory queries. He needed confidence that he could maintain customer relationships while managing rapid-fire negotiations.
The director didn’t need raw performance numbers. He needed early warning systems to help his team deliver better customer service.
None of them were asking for complex SQL with 10 different JOINs. They were asking: “How can I make our customers happier?”
6.2 Finally, let’s ask “how can I make our customers happier?”
After building all this technical sophistication—the four RAG systems, the agentic workflows, the intelligent decision making—let’s ask the question that matters most: “How can I make our customers happier?”. Woody does a great job listing actual actionable items with targetted reasons with numbers, not just some generic advises.
AI response to ‘how can I make our customer happier?’ full report
📊 Click to expand/collapse the detailed customer happiness analysis report
Customer Happiness Analysis Report
Executive Summary: Based on analysis of your lumber business data spanning 6-12 months, three major improvement areas have been identified that can significantly enhance customer happiness and retention.
Key Performance Indicators
- Order Fulfillment Time: 7 days average (last 30 days)
- Customer Retention Rate: 88.16% repeat customers vs 11.84% new customers
- Average Order Value: $16,000-$17,000 USD range for major customers
- Order Completion Rate: 894 orders completed on time in last 30 days
Top Customer Portfolio
Your top 5 customers represent significant volume concentration:
- Customer A - 23.1M FBM
- Customer B - 17.2M FBM
- Customer C - 15.3M FBM
- Customer D - 9.6M FBM
- Customer E - 6.8M FBM
🚀 THREE KEY RECOMMENDATIONS FOR CUSTOMER HAPPINESS
1. IMPLEMENT PREDICTIVE INVENTORY MANAGEMENT
Problem Identified: Seasonal volume fluctuations (30M FBM peak vs 12M FBM low) suggest inventory challenges
Solution: Develop AI-powered demand forecasting for top-selling products, create automated reorder points, implement real-time inventory visibility for sales team
Customer Impact: Reduced stockouts, faster quote turnaround times, more accurate delivery promises
2. ENHANCE DELIVERY RELIABILITY & COMMUNICATION
Problem Identified: 7-day average fulfillment time with no visibility into on-time delivery rates
Solution: Implement delivery tracking system with customer notifications, create delivery performance dashboards, establish delivery time commitments by product type and region
Customer Impact: Improved planning capability for customers, reduced anxiety about order status, better project scheduling
3. DEVELOP CUSTOMER-SPECIFIC PRICING & SERVICE TIERS
Problem Identified: High customer concentration risk with limited differentiation
Solution: Create tiered service levels based on volume and loyalty, implement dynamic pricing, develop exclusive product access for top-tier customers
📊 Expected Outcomes
Short-term (3-6 months):
- 15% improvement in order fulfillment time
- 90% customer satisfaction on delivery reliability
- 10% increase in repeat order frequency
Medium-term (6-12 months):
- 20% reduction in customer churn
- 25% improvement in average order value
- 95% on-time delivery rate achievement
Long-term (12+ months):
- 30% increase in customer lifetime value
- Market leadership in customer service
- Premium pricing capability vs competitors
🎯 Implementation Priority
- Phase 1 (Month 1-2): Delivery tracking and communication system
- Phase 2 (Month 2-4): Customer tier segmentation and service levels
- Phase 3 (Month 4-6): Predictive inventory management system
This analysis is based on actual business data and industry best practices. Regular monitoring and adjustment of these initiatives will be crucial for maximizing customer happiness and business growth.
TL;DR: Key Action Items
Based on the analysis, here are your key actions with specific reasons:
Immediate Actions (Next 30 Days)
Set up delivery tracking notifications - Your 7-day fulfillment time lacks visibility, causing customer anxiety about order status
Create inventory alerts for top 5 products - 2x4 and 2x6 Premium grades have 6,000+ orders but no stockout prevention system
Segment customers into 3 tiers by volume - 88% repeat customers deserve differentiated service based on their loyalty and volume
Short-term Actions (Next 90 Days)
Implement same-day quote response for top 10 customers - Major customers like A (23M FBM) need priority treatment to prevent churn
Deploy SMS/email order milestone updates - Customer communication gaps create uncertainty in project planning
Create dedicated account manager for Platinum tier - High-value customers generating $16K+ average orders need personal attention
Medium-term Actions (Next 6 Months)
Build predictive inventory dashboard - Monthly volume swings from 12M to 30M FBM require forecasting to prevent stockouts
Establish 95% on-time delivery KPI - No current delivery performance tracking means you can’t manage what you don’t measure
Develop volume-based pricing tiers - Customer retention at 88% could improve with loyalty incentives and exclusive pricing
Create customer portal with real-time order tracking - Reduce sales team interruptions from “where’s my order” calls
Set up automated reorder points - Prevent stockouts on your 6,471 most popular 2x4 Premium orders
6.2.1 What did Woody tool do exactly?
Woody answered following 8 questions by writing text-to-SQL solutions.
- “What are the top customer complaints or issues in recent sales data?”
→ Failed due to data not being available in the database
- “What is the average order fulfillment time for customers in the last 30 days?”
Click to view full response
The user is asking about the average time it takes to fulfill customer orders, calculated from the order creation date to the shipment completion date, for all orders completed within the last 30 calendar days until today, 2025-07-02.
Result: 7 days
Query executed:
WITH ShipmentCompletionDates AS (
SELECT
s.id AS shipment_id,
s.order_id,
MAX(l.created_on) AS shipment_completed_on
FROM
shipment AS s
JOIN
load AS l ON s.id = l.shipment_id
WHERE
s.status = 5 -- Shipment is completed
AND l.status IN (3, 4) -- Load is completed or invoiced
GROUP BY
s.id, s.order_id
)
SELECT
AVG(DATEDIFF(day, o.created_on, scd.shipment_completed_on)) AS AverageFulfillmentTimeDays
FROM
[order] AS o
JOIN
ShipmentCompletionDates AS scd ON o.id = scd.order_id
JOIN
client AS c ON o.client_id = c.id
WHERE
c.type = 1 -- Customers
AND o.created_on >= DATEADD(day, -30, '2025-07-02')
AND o.created_on <= '2025-07-02'
AND scd.shipment_completed_on IS NOT NULL
AND o.type = 1 -- Sales orders
AND o.status IN (1, 2, 3, 4);- “Show me the top 10 customers by volume in the last 6 months”
Click to view full response
The user is asking to see the top 10 customers based on the total volume of products they purchased, calculated from invoices over the last six months, ending today, 2025-07-02.
| Customer Name | Total Volume (FBM) |
|---|---|
| X0 | 23,078,355 |
| X1 | 17,153,247 |
| X2 | 15,257,468 |
| T3 | 9,574,907 |
| X5 | 6,818,221 |
| X6 | 6,655,537 |
| X7 | 6,543,042 |
| X8 | 6,510,736 |
| X9 | 5,938,692 |
| X10 | 4,877,345 |
SELECT TOP 10
c.name AS CustomerName,
SUM(CASE WHEN i.type = 1 THEN ir.fbm ELSE -ir.fbm END) AS TotalVolumeFBM
FROM client AS c
JOIN invoice AS i ON c.id = i.client_id
JOIN invoice_row AS ir ON i.id = ir.invoice_id
WHERE c.type = 1
AND i.created_on >= '2025-01-02'
AND i.created_on < '2025-07-03'
GROUP BY c.name
ORDER BY TotalVolumeFBM DESC;*- “How many orders were completed on time in the last 30 days?”
Click to view full response
The user is asking about the total number of contract orders that were completed on time within the last 30 calendar days, ending today, 2025-07-02. This will be calculated based on the order completion date.
Result: 894 orders
Query executed: SELECT COUNT(DISTINCT o.id) FROM [order] AS o WHERE o.status IN (3, 4) AND o.approved_on IS NOT NULL AND o.approved_on >= DATEADD(day, -30, GETDATE()) AND o.approved_on <= GETDATE();
- “What are the most common product types ordered by customers?”
Click to view full response
The user is asking about the most frequently ordered product types by customers, based on past invoice data. This shows which products, described by their category, species, thickness, width, grade, and surface, have been sold the most.
| Category | Species | Thickness | Width | Grade | Surface | Order Count |
|---|---|---|---|---|---|---|
| CLS | WHITE SPRUCE | 2.0 | 4.0 | PREMIUM | S4SEE | 6,471 |
| CLS | WHITE SPRUCE | 2.0 | 6.0 | PREMIUM | S4SEE | 6,074 |
| CLS | EURO SPF | 2.0 | 6.0 | PREMIUM | S4SEE | 4,037 |
| CLS | WHITE SPRUCE | 2.0 | 4.0 | #2 & BTR | S4SEE | 2,644 |
| CLS | WHITE SPRUCE | 2.0 | 4.0 | STD & BTR PREMIUM | S4SEE | 2,550 |
| CLS | EURO SPF | 2.0 | 4.0 | PREMIUM | S4SEE | 2,421 |
| CLS | EURO SPF | 2.0 | 4.0 | STD & BTR PREMIUM | S4SEE | 2,340 |
| CLS | WHITE SPRUCE | 2.0 | 6.0 | #2 & BTR | S4SEE | 1,943 |
| CLS | EURO SPF | 2.0 | 6.0 | MSR 1200 | S4SEE | 969 |
| CLS | EURO SPF | 2.0 | 6.0 | MSR 1650 | S4SEE | 956 |
This analysis shows the top 10 most frequently ordered lumber products, with 2x4 Premium White Spruce being the most popular with 6,471 orders.
SELECT
cat.name AS Category,
s.name AS Specie,
p.thickness AS Thickness,
p.width AS Width,
g.name AS Grade,
surf.name AS Surface,
COUNT(or_row.id) AS OrderCount
FROM order_row AS or_row
JOIN [order] AS o ON or_row.order_id = o.id
JOIN client AS c ON o.client_id = c.id
JOIN product AS p ON or_row.product_id = p.id
JOIN category AS cat ON p.category_id = cat.id
JOIN specie AS s ON p.specie_id = s.id
JOIN grade AS g ON p.grade_id = g.id
JOIN surface AS surf ON p.surface_id = surf.id
WHERE c.type = 1
AND o.type = 1
AND o.status IN (1, 2, 3, 4)
GROUP BY cat.name, s.name, p.thickness, p.width, g.name, surf.name
ORDER BY OrderCount DESC;*- “Show me sales volume trends by month for the last 12 months”
Click to view full response
The user is asking about the total sales volume in board feet (fbm) and sales value in currency, grouped by month, for the last 12 months, calculated from invoices.
| Sales Month | Total Volume (FBM) | Total Sale Value |
|---|---|---|
| 2024-07 | 20,719,147 | $10,597,342 USD |
| 2024-08 | 21,068,173 | $11,294,593 USD |
| 2024-09 | 15,449,793 | $8,745,868 USD |
| 2024-10 | 15,325,347 | $8,910,563 USD |
| 2024-11 | 14,774,399 | $9,504,878 USD |
| 2024-12 | 12,057,945 | $7,526,801 USD |
| 2025-01 | 20,035,561 | $12,587,360 USD |
| 2025-02 | 30,271,678 | $18,707,694 USD |
| 2025-03 | 17,379,510 | $11,444,785 USD |
| 2025-04 | 24,869,660 | $16,210,644 USD |
| 2025-05 | 22,429,698 | $13,532,364 USD |
| 2025-06 | 22,045,686 | $12,822,871 USD |
SELECT
FORMAT(DATEFROMPARTS(YEAR(i.created_on), MONTH(i.created_on), 1), 'yyyy-MM') AS SalesMonth,
curr.name AS Currency,
SUM(CASE WHEN i.type = 1 THEN ir.fbm ELSE -ir.fbm END) AS TotalVolumeFBM,
SUM(CASE WHEN i.type = 1 THEN ir.value ELSE -ir.value END) AS TotalSaleValue
FROM invoice AS i
JOIN invoice_row AS ir ON i.id = ir.invoice_id
JOIN currency AS curr ON i.currency_id = curr.id
WHERE i.created_on >= DATEADD(month, -12, DATEFROMPARTS(YEAR(GETDATE()), MONTH(GETDATE()), 1))
AND i.created_on < DATEFROMPARTS(YEAR(GETDATE()), MONTH(GETDATE()), 1)
GROUP BY FORMAT(DATEFROMPARTS(YEAR(i.created_on), MONTH(i.created_on), 1), 'yyyy-MM'), curr.name
ORDER BY SalesMonth, Currency;*- “What is the percentage of repeat customers vs new customers in the last 6 months?”
Click to view full response
The user is asking for the percentage of customers who have made previous purchases compared to customers making their first purchase, over the last six months until today, 2025-07-02. This will be calculated using invoice data.
| New Customers | Repeat Customers | Percentage New Customers | Percentage Repeat Customers |
|---|---|---|---|
| 9 | 67 | 11.84% | 88.16% |
DECLARE @StartDate DATE = '2025-01-02';
DECLARE @EndDate DATE = '2025-07-02';
WITH ClientsInPeriod AS (
SELECT DISTINCT i.client_id
FROM invoice AS i
WHERE i.created_on >= @StartDate
AND i.created_on <= @EndDate
),
ClientFirstInvoice AS (
SELECT i.client_id, MIN(i.created_on) AS FirstInvoiceDate
FROM invoice AS i
GROUP BY i.client_id
),
CategorizedClients AS (
SELECT cip.client_id,
CASE
WHEN cfi.FirstInvoiceDate >= @StartDate AND cfi.FirstInvoiceDate <= @EndDate THEN 'New'
WHEN cfi.FirstInvoiceDate < @StartDate THEN 'Repeat'
ELSE 'Other'
END AS CustomerType
FROM ClientsInPeriod AS cip
JOIN ClientFirstInvoice AS cfi ON cip.client_id = cfi.client_id
JOIN client AS c ON cip.client_id = c.id
WHERE c.type = 1
)
SELECT
SUM(CASE WHEN cc.CustomerType = 'New' THEN 1 ELSE 0 END) AS NewCustomersCount,
SUM(CASE WHEN cc.CustomerType = 'Repeat' THEN 1 ELSE 0 END) AS RepeatCustomersCount,
CAST(SUM(CASE WHEN cc.CustomerType = 'New' THEN 1 ELSE 0 END) AS DECIMAL(10, 2)) * 100.0 / NULLIF(COUNT(cc.client_id), 0) AS PercentageNewCustomers,
CAST(SUM(CASE WHEN cc.CustomerType = 'Repeat' THEN 1 ELSE 0 END) AS DECIMAL(10, 2)) * 100.0 / NULLIF(COUNT(cc.client_id), 0) AS PercentageRepeatCustomers
FROM CategorizedClients AS cc;*- “What is the average order value for customers in the last 6 months?”
Click to view full response
The user is asking about the average sales value per customer based on invoices from the last six months, ending today, 2025-07-02. This will be calculated in USD, CAD, and EUR.
| Customer Name | Average Order Value |
|---|---|
| X1 | $16,250.92 USD |
| X2 | $19,032.00 USD |
| X3 | $17,133.61 USD |
| X4 | $18,173.33 USD |
| X5 | $16,586.25 USD |
| X6 | $16,397.12 USD |
| X7 | $16,806.07 USD |
| X8 | $12,192.53 USD |
| X9 | $16,688.64 USD |
| X10 | $16,281.59 USD |
| X11 | $16,346.64 USD |
| X12 | $16,095.01 USD |
| X13 | $22,905.07 USD |
| X14 | $17,320.94 USD |
| … and 58 more customers with average order values ranging from $2,713 to $22,905 | |
This analysis shows the average order value for all 72 customers active in the last 6 months, with values ranging from $2,713 to $22,905 USD per order.
WITH InvoiceTotals AS (
SELECT
i.id AS InvoiceID,
i.client_id,
i.currency_id,
SUM(CASE WHEN i.type = 1 THEN ir.value ELSE -ir.value END) AS TotalInvoiceValue
FROM invoice AS i
JOIN invoice_row AS ir ON i.id = ir.invoice_id
WHERE i.created_on >= '2025-01-02 00:00:00'
AND i.created_on <= '2025-07-02 23:59:59'
GROUP BY i.id, i.client_id, i.currency_id
)
SELECT
c.name AS CustomerName,
curr.name AS Currency,
AVG(it.TotalInvoiceValue) AS AverageOrderValue
FROM InvoiceTotals AS it
JOIN client AS c ON it.client_id = c.id
JOIN currency AS curr ON it.currency_id = curr.id
WHERE c.type = 1
GROUP BY c.name, curr.name
ORDER BY CustomerName, Currency;*