If audio can be vectorized, then we can do distance search by similarity.
The trick is the chunking stage. Instead of embedding the whole song, user’s audio file is chunked into N. For each N, K many top results are returned.
Return top 10 similar songs using score fusion (voting + distance); Recommendation complete
image.png
Development Stage
Data Collection:
Open source audio dataset
Chunk Processing:
Chunk all audio files into clip of 5-10second audio chunks.
Each chunk → embedding via Wav2Vec2
[optional] Store embedding as dictionaries {‘file_name’,‘chunk_id’,‘embedding’}
[optional] Store chunked audio in database {‘chunk_id’, audio_fileX.wav}
Inference Stage
Chunk Processing:
Input audio split into 5-10second chunks
Each chunk → embedding via Wav2Vec2
FAISS Search:
Each chunk embedding queries FAISS index
Returns top 5 matches per chunk (distance + index)
Standard_NC6s_v3 (6 cores, 112 GB RAM, 736 GB disk) Azure ML studio
1.1 Webapp (beta release 2025-03-14)
frontend: React application ✅
backend: FastAPI/Flask microservice ✅
embedding/vector search services: REST API via Databricks Model Serving ✅
CI/CD: GitHub actions ✅
2. CLAP musical embedding model
Development stage (embedding)
compute time: 48 hours+ to embed 13171 classical music audio files. on Standard_NC6s_v3 (6 cores, 112 GB RAM, 736 GB disk) GPU
database: Azure Blob Storage to store 10 second clips and whole songs separately
vector database: list of dictionaries {‘chunk_id’, ‘embedding’, ‘filename’} pickled and stored in Databricks Unity Catalog. Then loaded and saved onto faiss vector store instance.
2.1 Results
Below are two simple tests.
Testing an audio file that already exists in the database. So the top recommendation should be the exact same file.
Testing an audio file that doesn’t exists in the database.
How to interpret
Rank & File Name
Position in similarity ranking (1 = most similar)
Source file from your database
Combined Score
(Vote Score × 0.2) + (Similarity Score × 0.8)
Primary ranking metric (higher = better match)
Votes
Number of input chunks matching this file
More chunks matched → higher confidence
Total Similarity
Aggregate similarity across all matches
Higher = more cumulative similarity
Audio Players
Input Sample: Your original audio chunk being compared
Recommended Match: Database clip matched to your input
Distance: 0 = identical, <0.2 = very similar, >0.5 = less similar
2.1.1 Test 1 - successfully retrieves the original file
# %% [Execution]if__name__=="__main__": logging.info("Starting analysis pipeline") logging.info("TEST 1 - MUSIC ALREADY IN DATABASE") analyze_audio('../data/inputs/FilePMLP1020413-C.Mantione II. Nausicaa.mp3', max_recommendations=2, max_similar_clips=2,max_input_comparison=2) logging.info("Analysis completed successfully")
Recommendations
Rank 1: FilePMLP1020413-C.Mantione II. Nausicaa.mp3
Combined Score: 1.0000
Votes: 92 | Total Similarity: 81.41
Input Sample 1:
Match 1: Distance 0.0000
Input Sample 2:
Match 1: Distance 0.0000
Match 2: Distance 0.1209
Rank 2: FilePMLP22468-01.01. A Faust Symphony- I - Faust.mp3
Combined Score: 0.0525
Votes: 5 | Total Similarity: 4.23
Input Sample 1:
Match 1: Distance 0.1406
Input Sample 2:
Match 1: Distance 0.1455
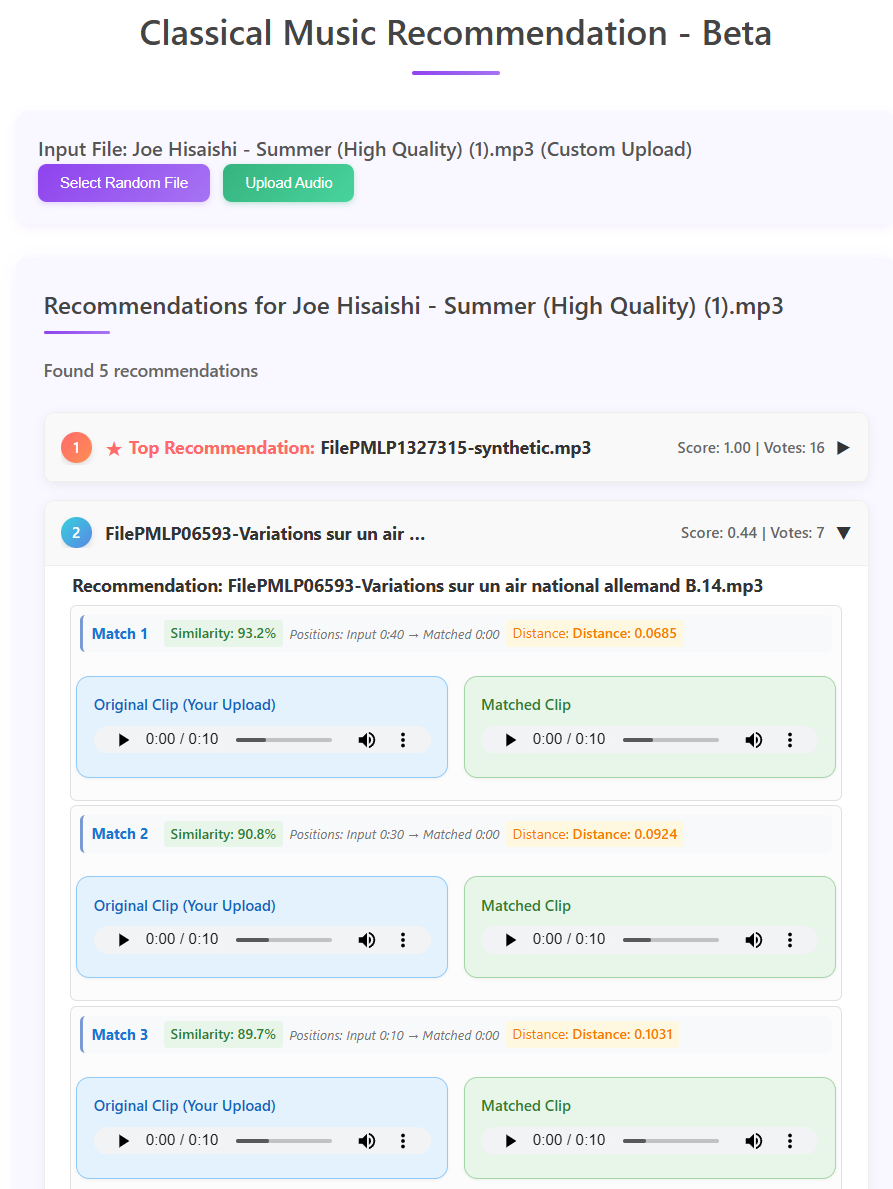
2.1.2 Test 2 - successfully retrieves similar songs
# %% [Execution]if__name__=="__main__": logging.info("Starting analysis pipeline") logging.info("TEST 2 - MUSIC NOT IN DATABASE") analyze_audio('../data/inputs/Joe Hisaishi - Summer (High Quality).mp3', max_recommendations=2, max_similar_clips=2,max_input_comparison=2) logging.info("Analysis completed successfully")
Recommendations
Rank 1: FilePMLP1327315-synthetic.mp3
Combined Score: 1.0000
Votes: 16 | Total Similarity: 14.80
Input Sample 1:
Match 1: Distance 0.0537
Match 2: Distance 0.0843
Input Sample 2:
Match 1: Distance 0.0542
Match 2: Distance 0.0660
Rank 2: FilePMLP06593-Variations sur un air national allemand B.14.mp3
Combined Score: 0.4373
Votes: 7 | Total Similarity: 6.47
Input Sample 1:
Match 1: Distance 0.0685
Match 2: Distance 0.0703
Input Sample 2:
Match 1: Distance 0.0924
Overall, the result is very satisfactory.
Potential improvements
Issue #1: sometimes there’s just ‘clapping’ clips or ‘silence’ clips. These can be clustered and removed
Issue #2: model can be further improved with finetuning