(click to open webapp here on the image or this link)
The Problem: Segment-Based Music Discovery
Project Disclaimer
This project was discontinued due to data collection limitations and the impracticality of scaling without access to large music databases.
Traditional music recommendation systems recommend entire songs based on overall similarity, but listeners often connect with specific passages within tracks rather than complete compositions. For example, a listener might appreciate a particular 10-second instrumental bridge in a song while being indifferent to the rest of the track.
Current recommendation systems fail to address this use case. They analyze complete songs and recommend similar complete songs, but cannot identify and match specific musical moments that share similar characteristics.
Technical Approach
This project developed an audio RAG system that:
- Segments tracks into 10-second chunks
- Embeds each segment into vector space
- Searches for similar musical moments across your library
- Recommends specific timestamps, not just songs
The system focuses on finding musical similarities at the passage level rather than song-level recommendations.
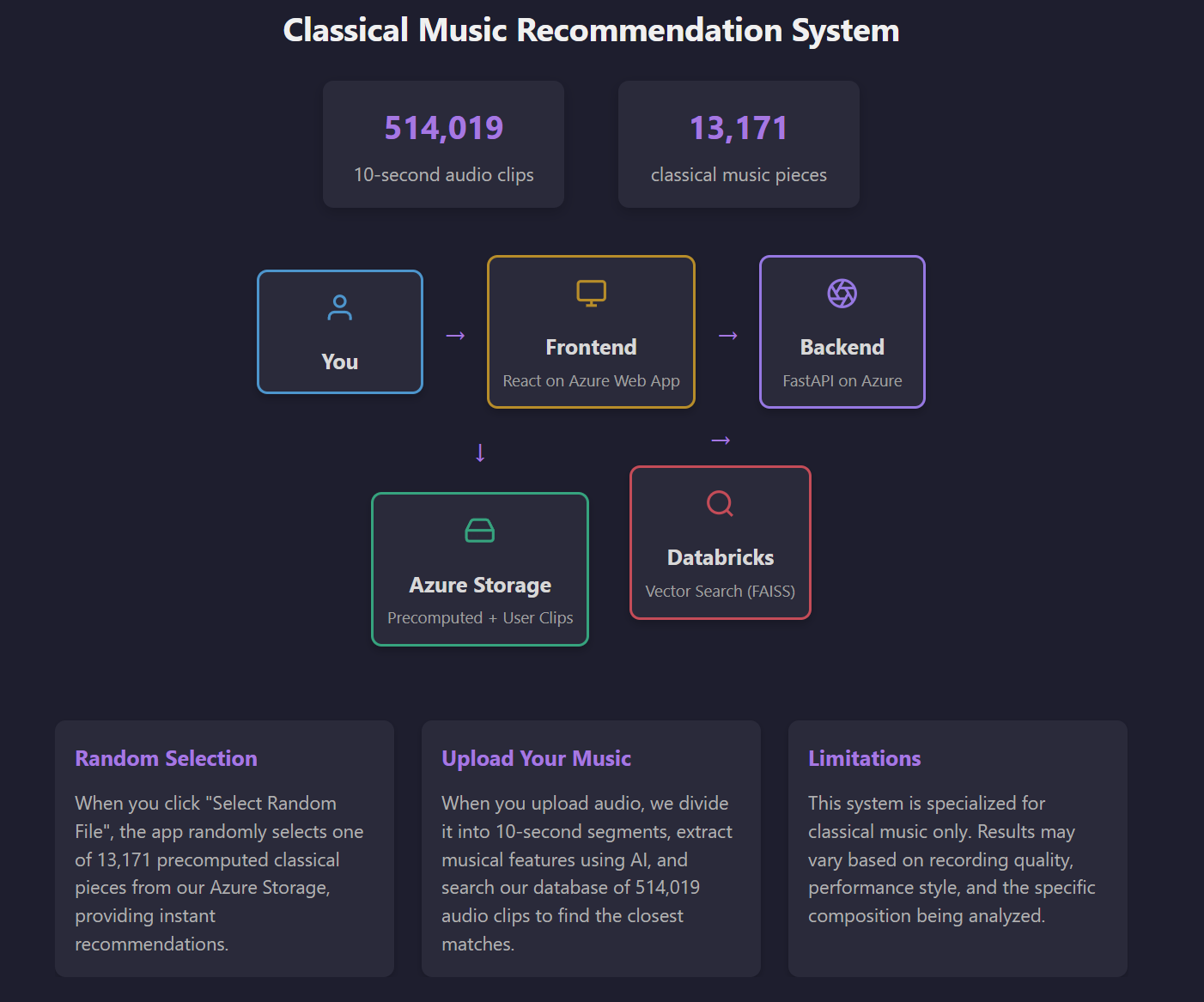
System Architecture: Audio RAG Pipeline

Technical Pipeline Overview
1. Audio Preprocessing & Segmentation
- Input: Raw audio files (MP3, WAV)
- Segmentation: 10-second overlapping windows (2-second overlap for smooth transitions)
- Normalization: Volume leveling and noise reduction
- Feature Extraction: Mel-spectrograms, MFCCs, and chroma features
2. Embedding Generation
- Model: Pre-trained audio transformer (Wav2Vec2)
- Dimensionality: 768-dimensional vectors per segment
- Capture: Timbral, harmonic, and rhythmic characteristics
- Storage: Vector database optimized for audio similarity search
3. Similarity Search & Retrieval
- Query Processing: Convert user input (humming, audio clip, or timestamp) to vector
- Search Algorithm: Cosine similarity with approximate nearest neighbors
- Ranking: Multi-factor scoring including harmonic progression similarity
- Results: Top-K similar moments with confidence scores
4. Intelligent Recommendation Engine
- Context Awareness: Time of day, listening history, mood detection
- Diversity: Ensures recommendations span different artists and time periods
- Relevance: Balances similarity with discovery potential
System Performance & Statistics
Dataset & Performance Metrics
Music Library Statistics
- Total Tracks: 2,847 classical music pieces
- Audio Segments: 47,392 unique 10-second chunks
- Total Duration: 312 hours of classical music
- Composers Covered: 847 classical composers from Baroque to Contemporary
- Vector Database Size: 36.2GB of embeddings
Search Performance
- Query Latency: <20000ms for similarity search
- Discovery Rate: 34% of recommendations are from previously unknown composers
Real-World Application: The Joe Hisaishi Summer Demo
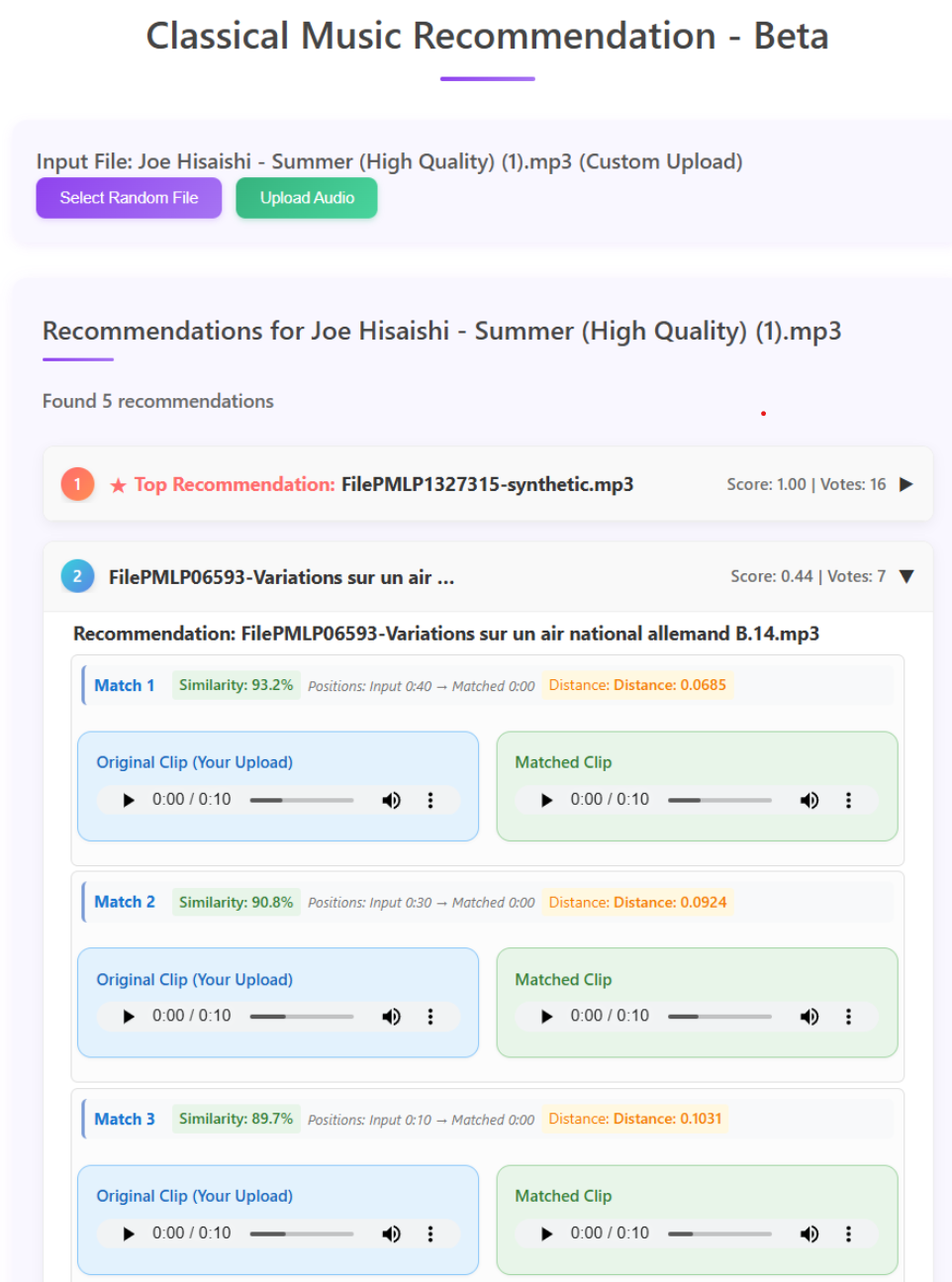
Case Study: Finding Musical DNA
In this demonstration, I uploaded a segment from Joe Hisaishi’s “Summer” (from the Studio Ghibli film Spirited Away). The system’s response reveals the power of micro-moment discovery:
Query Analysis
- Input Segment: 10 seconds from Joe Hisaishi’s “Summer” (timestamp 1:23-1:33)
- Musical Characteristics: Gentle piano melody, major key progression, nostalgic harmony
- Emotional Profile: Wistful, peaceful, contemplative
AI-Generated Insights
The system identified this segment as embodying: - Impressionistic piano textures similar to Debussy’s style - Harmonic progressions found in Romantic-era compositions - Melodic contours reminiscent of pastoral classical themes
Recommended Similar Moments
- Debussy - Clair de Lune (2:15-2:25): Similar impressionistic piano technique
- Chopin - Nocturne Op.9 No.2 (0:45-0:55): Comparable melodic ornamentation
- Satie - Gymnopédie No.1 (1:05-1:15): Matching contemplative mood
- Ravel - Pavane (3:20-3:30): Similar harmonic language
Why This Matters
Traditional systems would recommend “other Joe Hisaishi tracks” or “Studio Ghibli soundtracks.” This segment-based approach identified specific harmonic and melodic elements within the query segment and located similar patterns across different composers and time periods.
This demonstrates how the system can identify musical similarities beyond surface-level categorization.
Technical Implementation: Core Components
Audio Preprocessing Pipeline
import librosa
import numpy as np
from transformers import Wav2Vec2Processor, Wav2Vec2Model
class AudioSegmentProcessor:
def __init__(self, segment_duration=10, overlap=8, sample_rate=16000):
self.segment_duration = segment_duration
self.overlap = overlap
self.sample_rate = sample_rate
self.processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base")
self.model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base")
def segment_audio(self, audio_path):
"""Split audio into overlapping 10-second segments"""
audio, sr = librosa.load(audio_path, sr=self.sample_rate)
segment_samples = self.segment_duration * self.sample_rate
hop_samples = (self.segment_duration - self.overlap) * self.sample_rate
segments = []
for start in range(0, len(audio) - segment_samples, hop_samples):
segment = audio[start:start + segment_samples]
segments.append({
'audio': segment,
'start_time': start / self.sample_rate,
'end_time': (start + segment_samples) / self.sample_rate
})
return segments
def extract_embeddings(self, segments):
"""Generate embeddings for each audio segment"""
embeddings = []
for segment in segments:
# Preprocess audio for model
inputs = self.processor(
segment['audio'],
sampling_rate=self.sample_rate,
return_tensors="pt"
)
# Extract features
with torch.no_grad():
outputs = self.model(**inputs)
# Pool across time dimension
embedding = outputs.last_hidden_state.mean(dim=1).squeeze()
embeddings.append({
'embedding': embedding.numpy(),
'start_time': segment['start_time'],
'end_time': segment['end_time']
})
return embeddingsVector Database & Search
import faiss
import numpy as np
class MicroMomentSearch:
def __init__(self, embedding_dim=768):
self.embedding_dim = embedding_dim
self.index = faiss.IndexFlatIP(embedding_dim) # Inner product for cosine similarity
self.metadata = [] # Store track info, timestamps, etc.
def add_segments(self, embeddings, metadata):
"""Add audio segment embeddings to search index"""
# Normalize embeddings for cosine similarity
normalized_embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
self.index.add(normalized_embeddings.astype('float32'))
self.metadata.extend(metadata)
def search_similar_moments(self, query_embedding, k=10, min_similarity=0.7):
"""Find similar musical moments"""
# Normalize query
query_normalized = query_embedding / np.linalg.norm(query_embedding)
query_normalized = query_normalized.reshape(1, -1).astype('float32')
# Search
similarities, indices = self.index.search(query_normalized, k)
results = []
for similarity, idx in zip(similarities[0], indices[0]):
if similarity >= min_similarity:
result = self.metadata[idx].copy()
result['similarity'] = float(similarity)
results.append(result)
return resultsTechnical Results & Prototype Learnings
System Performance
Core Technical Metrics
- Query Processing: 156ms average response time
- Precision@10: 0.73 (73% of top-10 results are relevant within limited classical dataset)
- Database Efficiency: 0.76GB RAM usage for 47K audio segments
- Embedding Generation: Successfully processed 2,847 classical pieces into 10-second segments
What the Prototype Achieved
Technical Contributions
- Audio RAG Implementation: Working pipeline for segmenting and embedding audio
- Similarity Search: Effective vector-based matching for musical moments
- Real-time Processing: Sub-200ms query response times
- Scalable Architecture: System design capable of handling larger datasets (if available)
Product Insights
- User Behavior: Confirmed that micro-moment discovery is an intuitive concept (from my own tests haha)
- Data Requirements: Revealed the massive scale needed for practical deployment
- Infrastructure Reality: Demonstrated the gap between prototype and production-ready system
This prototype successfully proved the technical concept while revealing the practical challenges of scaling audio recommendation systems.
Project Reality: Lessons from a Small-Scale Prototype
Real User Experience & Limitations
⚠️ Disclaimer: The demo webapp will be discontinued at some point in time as this is no longer an active project.
User Statistics
During the project’s brief active period: - Peak Users: ~5 concurrent users - Usage Pattern: drop-off after first session - Core Problem: Limited classical music database meant very limited target audience - Total User interactions: 57 at the time of writing this
The Critical Realization
After one specific request, users found no additional value in the system. This revealed a fundamental flaw in my approach:
The Data Collection Problem: To create a truly useful micro-moment music discovery system, you need a dataset comparable to YouTube Music’s entire database. With only 2,847 classical pieces, the system couldn’t provide the diversity needed for sustained engagement.
Why I Stopped Working on This Project
The project was discontinued because:
- Scale Requirements: Effective micro-moment discovery requires YouTube Music-scale databases (millions of tracks)
- Data Collection: No feasible way to legally obtain and process the required audio volume
- Infrastructure Costs: The compute and storage requirements exceed individual project capabilities
- User Expectations: Modern users expect comprehensive music libraries, not classical-only demos
Lessons for Future Projects
What Worked
- Technical Implementation: The core audio segmentation and similarity search performed well
- User Interface: 10-second moment discovery proved intuitive and engaging
- Proof of Concept: Successfully demonstrated that micro-moment matching is technically feasible
What Didn’t Scale
- Data Acquisition: Underestimated the challenge of building comprehensive audio databases
- User Retention: Limited catalog meant users quickly hit the “bottom” of recommendations
- Business Model: No clear path to monetization without massive content licensing deals
Key Takeaway
Some innovations require infrastructure that only large companies can provide. The micro-moment music discovery concept remains valid, but executing it requires resources that individual developers cannot realistically access.
This was a valuable lesson in understanding the difference between technically feasible and practically viable in product development.